




 学校概况
学校概况
 报考理由
报考理由
 学校纵览
学校纵览
 好学成电
好学成电
 国际交流
国际交流
 高考报道
高考报道
 光影成电
光影成电
 招生政策
招生政策
 招生章程
招生章程
 特殊类型
特殊类型
 招生计划
招生计划
 历年分数
历年分数
 常见问题
常见问题
 专业目录
专业目录
 选科要求
选科要求
 学科交叉
学科交叉
 招生专业
招生专业
 院系设置
院系设置
 重点学科
重点学科
 就业质量报告
就业质量报告
 就业相关新闻
就业相关新闻
 联系本科招办
联系本科招办

——大媒体计算中心徐行博士提出挖掘跨模态数据关联的新方法
学术界对“多媒体检索”的认识又向前迈出了重要一步!近日,我校计算机学院大媒体计算中心徐行博士以第一作者在国际顶级期刊IEEE Transactions on Image Processing(TIP)上发表研究论文,提出了一种新的检索方法,从而使跨媒体检索技术(cross-media retrieval)的综合效率提高了大约5%。
跨媒体检索一直是计算机视觉领域的研究重点和难点。近年来,随着文本、图片、视频、音频、传感器数据等不同类型的多媒体数据的快速增加,如何实现不同模态间的数据检索已经成为多媒体检索领域的研究热点。然而,如何“教”会计算机在不同模态的信息海洋中寻找数据之间的关联,一直是困扰学界和业届的难题。
“虽然目前的研究成果只是仿真的结果,但它在解决跨模态数据关联方面的进展,向我们预示了一种美好的前景。”徐行表示,业内已经有许多跨媒体检索技术,但实际效果各有长短,而他的方法在性能上比业内常见的方法提升了一个层级,从而使“跨媒体检索”展现出了更加迷人的魅力。

前奏:三人合作,一炮而红
当徐行在攻读硕士和博士学位之时,也正是“跨媒体检索”技术快速发展、行业需求日益强烈的几年。据报道,2013年仅Facebook的10多亿用户每天就可以上传3.5亿张照片,每天发布的各种内容多达47.5亿条(包括照片、评论和状态更新等),每天产生的消息总量达到100亿条,公司的基础设施中存储的数据总量已达到250PB。
“互联网上每天都产生海量的数据,数据的模态也早已超越文字、图片、音频、视频,向更丰富、更复杂的维度延伸!”徐行说,如果说以前的用户会满足于用“关键词”搜索网页、图片、视频等信息或用图片搜索图片,那么,未来的用户需求必将朝着多媒体数据跨模态搜索的方向发展。
2015年,当时还在九州大学攻读博士学位的徐行在一次国际学术会议中认识了电子科技大学计算机学院的申恒涛教授和沈复民副教授。其中,申恒涛教授已在国际上率先实现了海量视频数据实时内容搜索;沈复民副教授在机器学习、计算机视觉、模式识别等方面也有相当的学术成果积累。
这年11月,徐行与申恒涛、沈复民决定联合开展多媒体检索问题研究。不久,他们的研究成果就以论文形式投稿到国际著名学术会议——ACM多媒体检索大会ICMR(International Conference on Multimedia Retrieval),并在大会上引起同行的关注与好评,因为他们的方法在性能上已经超过了迄今为止国际上最先进的方法。
这项研究成果为三人此后的合作铺平了道路。2016年2月,徐行正式加盟电子科技大学,成为申恒涛教授团队中的一员。
超越:百尺竿头,更进一步
在ACM多媒体检索大会ICMR上的丰硕收获,让徐行更加深刻地认识到继续深入研究下去的意义和前景。回看这项研究,他认为,这篇“打前站”的研究论文有很多不足之处:
首先,这项研究只是在较小的范围内做实验或验证,模拟了跨模态、跨媒体搜索的关键技术。这一点与当今数据量爆炸式增长对跨媒体检索的要求相比还有很大的距离。其次,这项研究聚焦的问题更侧重于模型本身,问题的设定比较简单、明确,方法的设计也更多地考虑理论上的性能和精确度,这一点与行业应用的要求还有很大的距离。
因此,接下来的研究,他们最高的标准就是最大限度地满足行业对跨媒体检索的要求,而他们最大的对手就是他们自身。针对前期研究的不足,他们分析认为,要解决多媒体搜索的问题,关键就在于:第一,如何挖掘多模态数据之间的关联性;第二,如何迎接海量数据的考验;第三,如何最大限度地提高存储效率。
“解决这三个方面中的每一个问题,都是很有难度的。”徐行举例说,要让计算机在海量数据中寻找相关性数据,这对算法是一大考验;而要“教”会计算机在不同模态数据中辨别数据之间是否具有关联性,就如同要教一个2岁的孩子知道“斑马”两个字和动物园中的某一种动物的对应关系。
传统的解决办法是跨模态哈希(Cross-Modal Hashing)技术,即通过构造哈希函数,将不同模态数据的高维特征映射成低维的二进制哈希编码,并在“汉明空间”中保持了高维特征的空间结构。这种方法具有存储所需空间小和检索速度快的优点。问题在于,传统的跨模态检索方法,尤其以哈希算法为主的检索方法,通常需要较高的时间复杂度来获取相关的哈希码字和相关的编码函数。
“通俗地说,跨媒体检索要在检索效率、准确性和存储效率三个方面做出综合取舍,到目前还没有一种解决办法能够三者兼顾,或在三个方面都做到极致!”徐行说。那么,徐行他们能够创造奇迹吗?
成果:方法奇特,指标一流
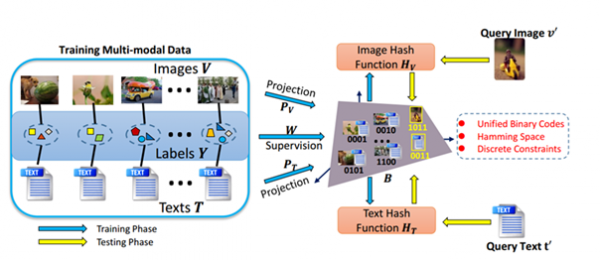
论文中提出的基于线性判别分类的统一哈希表示学习框架
经过深入研究,他们在对比与分析传统的跨模态哈希算法的基础上,提出了一种基于线性判别分类的统一哈希表示学习框架,创新性地将不同模态的哈希函数、统一哈希表示以及线性分类器进行联合学习。
在维基百科等多模态数据集的搜索验证性实验中,他们提出的方法能以更快的训练速度得到非常令人满意的跨模态检索性能,而且采用统一的哈希码表示,能更有效地节省多模态数据的存储空间。实验证明,该方法可以很好地应用于异构数据搜索等实际问题中。
据介绍,改进后的方法在仿真的跨模态检索实验中检索单张图片的时间仅为13毫秒,也就是说,在1秒之内它可以检索出70多张图片;而且,模拟试验的数据规模也从最初的几万条多模态数据扩展到了如今的数百万高维异构数据。
徐行解释说,挖掘和抽取不同模态数据之间的关联,是改进方法的核心和最大的亮点。“每年会有很多人来电子科大看银杏,拍照片、发说说、发帖子、分享视频……现在,有这种方法做支撑,我们的系统只要捕捉到一张游客发布的银杏图片,就可以检索出与之对应的所有的文字、语音、视频及其他数据。”他说。
据了解,徐行博士提出的这一方法目前已经转化成比较实用的产品,应用在了在线教育公司的相关服务中。徐行很有信心地说,“以后,这种方法还可以向物联网、信息医疗等更加广阔的领域进军,在更加广阔的领域发挥作用。”

